
内存泄露排查
背景
服务内存使用率一直上涨,quota已达28G,近三天内存使用率达从60上涨到70%以上,上涨幅度3G左右;基本可排除词典本身上涨原因;同时策略对词典有强依赖;故需通过排查内存泄漏原因并修复.
编译
编译配置文件中需要新增
1 | CONFIGS('xxxx/tcmalloc@tcmalloc_V2.7.0.7_GCC820_4U3_K3_GEN_PD_BL', Libraries('libtcmalloc_and_profiler.a')) |
或者使用gperftools也可以,gperftools其中就包括了tcmalloc工具`
1 | CONFIGS('xxxx/gperftools@gperftools_V2.0.0.1_GCC820_4U3_K3_GEN_PD_BL@git_tag',Libraries('libtcmalloc_and_profiler.a')) |
同时,CPPFLAGS需要增加:
1 | -DBAIDU_RPC_ENABLE_HEAP_PROFILER |
CFLAGS增加:
1 | -fno-omit-frame-pointer |
最后,最重要的是,需要在shell中执行:`
1 | export TCMALLOC_SAMPLE_PARAMETER=524288 |
否则,会出现下面的错误:
获取rpc_view`
1 | PREVDIR=`pwd` && TEMPDIR=`mktemp -d -t build_rpc_view.XXXXXXXXXX` && git clone xxxxx_rpc $TEMPDIR xxx/baidu-rpc && cd $TEMPDIR xxx/baidu-rpc && bcloud local -j8 && make -sj8 && cp -f ./output/bin/rpc_view $PREVDIR && cd $PREVDIR; rm -rf $TEMPDIR |
./rpc_view ip:port 执行,然后访问服务端口,例如:
1 | ./rpc_view 1.2.3.4:2024 |
可以看到rpc的相关状态: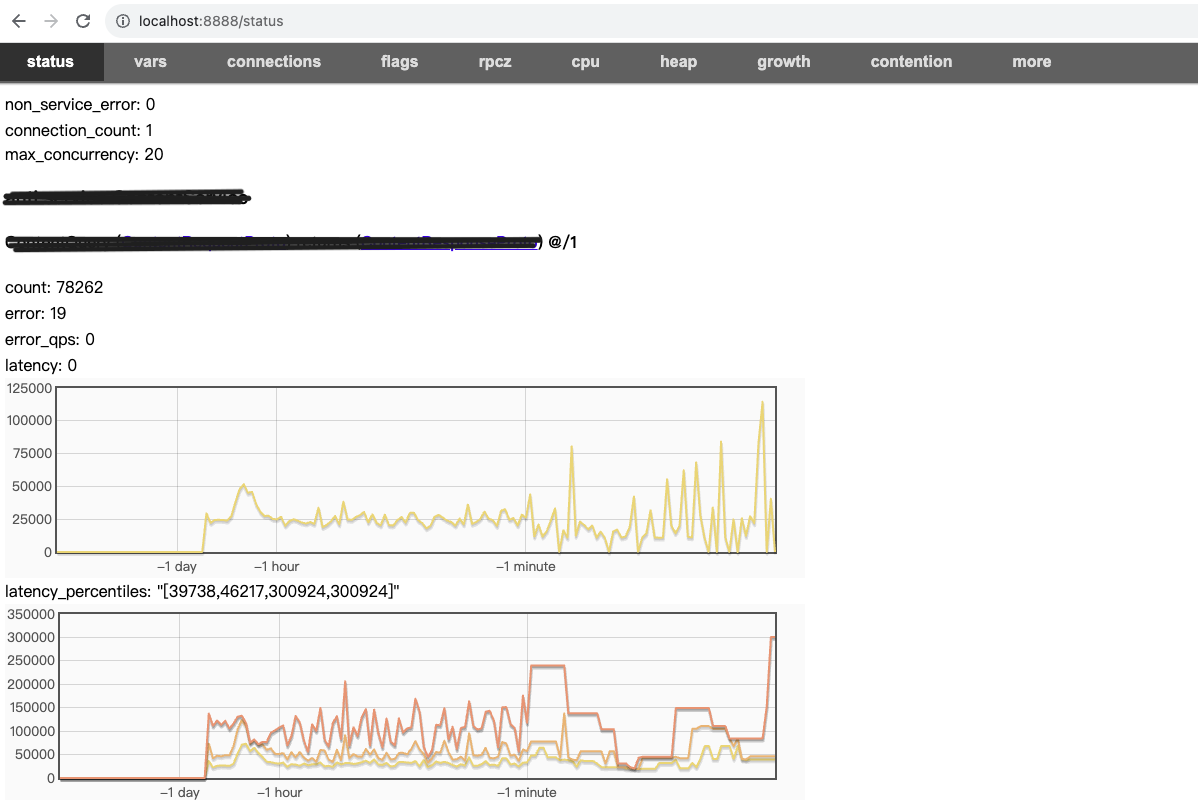
heap_profiler
出现超时可以尝试多次刷新,或者可以在页面url的最后添加:&seconds=100,重新刷新几次。
heap_profiler会在一段时间保存一个记录点,例如xxxxxxx.heap,即内存快照
在view中可以看到某个记录点的内存使用情况
其中Display Type是选择通过什么形式进行展示,这里可以选择dot形式,个人觉得最为直观
选择diff中的记录点则表示当前view的记录点和diff的记录点进行比较,可以用来看到具体某个函数的内存增长情况。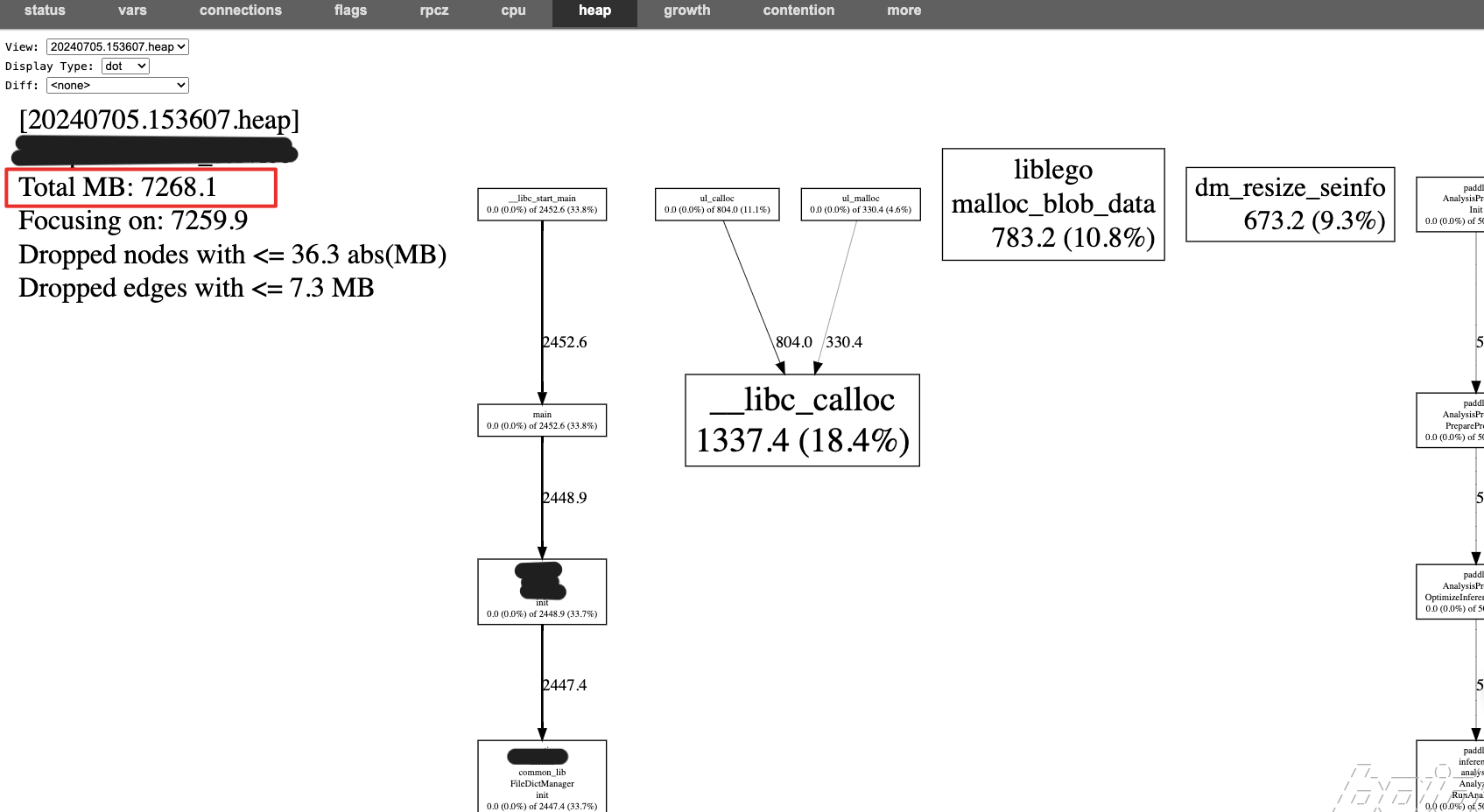
分析
1 构建
服务中使用的gperftools第三方工具,gperftools中包含tcmalloc,所以无需额外添加第三方库
2 环境变量
opear容器的环境变量无法通过提交代码CR修改部署脚本的方式进行修改
正确的修改方式是,更新部署,在部署时添加上环境变量
只有添加环境变量后,export TCMALLOC_SAMPLE_PARAMETER=524288才可以使用heap profiler工具
这是因为tcmalloc工具,在启动bin之前,需要从TCMALLOC_SAMPLE_PARAMETER中读取值,所以也无法动态添加,必须在启动bin之前
3 排查
启动服务一段时间后,分别选择两个内存快照点进行diff,结果显示,dm_pack_create函数出现了内存泄露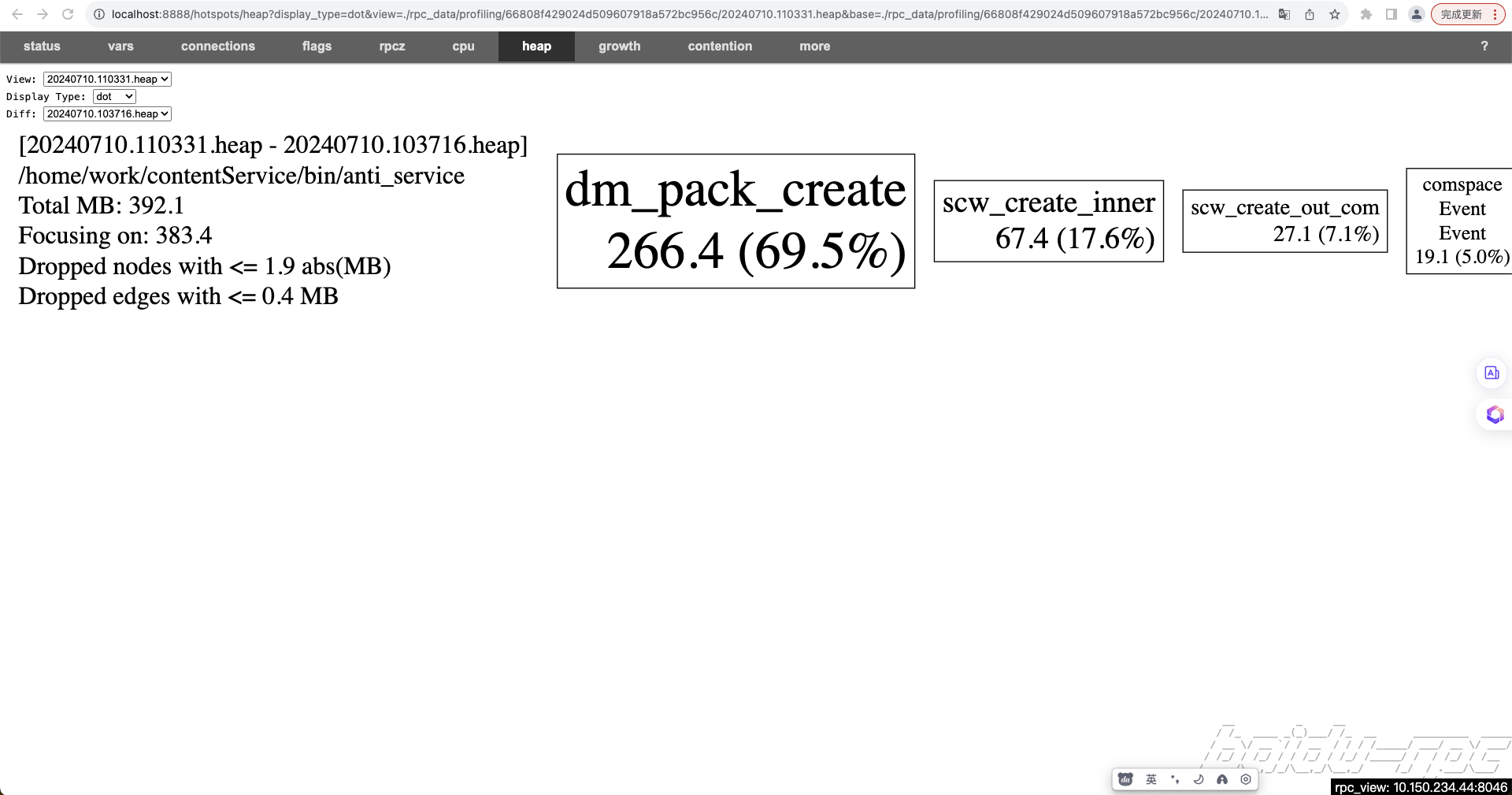
dm_pack_create函数与服务使用的词表有关系
仅 dqa_multi_term_string_match_dict 和 string_match_with_space 两个词表是服务独有的
进一步分析发现,dqa_multi_term_string_match_dict中 p_dm_pack没有释放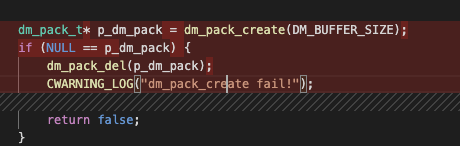
应该修改成: